FAIR by Design
Findable, Accessible, Interoperable, and Reusable data from day one.
OpenAI v1-Compatible API for R&D
Turn mixed lab records into FAIR-aligned data assets. Blobfish helps teams move from experiment records to analysis-ready data using repeatable extraction and mapping workflows.
Findable, Accessible, Interoperable, and Reusable data from day one.
Connect captured metadata to modeling and analytics workflows.
Audit-ready provenance and consistent vocabulary alignment.
Even with major digital programs, lab context is often still spread across logbooks, mixed-language notes, PDF reports, and equipment files.
Multi-Modal Input Data
Blobfish converts scans, tables, logs, and reports into structured metadata that teams can query, review, and reuse.

Use a focused API workflow to ingest, interpret, and structure R&D records into a queryable knowledge graph.
Scanned pages, scientific articles, equipment logs, and databases.
Extract key entities, variables, parameters, and relationships automatically.
Align local terms to standard ontologies and create a unified schema.
Deliver FAIR-aligned data to downstream tools and decision makers.
Built for scientific data workflows that need repeatable extraction, mapping, and review.
Selected screenshots from the Blobfish presentation showing the architecture and model-handler workflow in action.
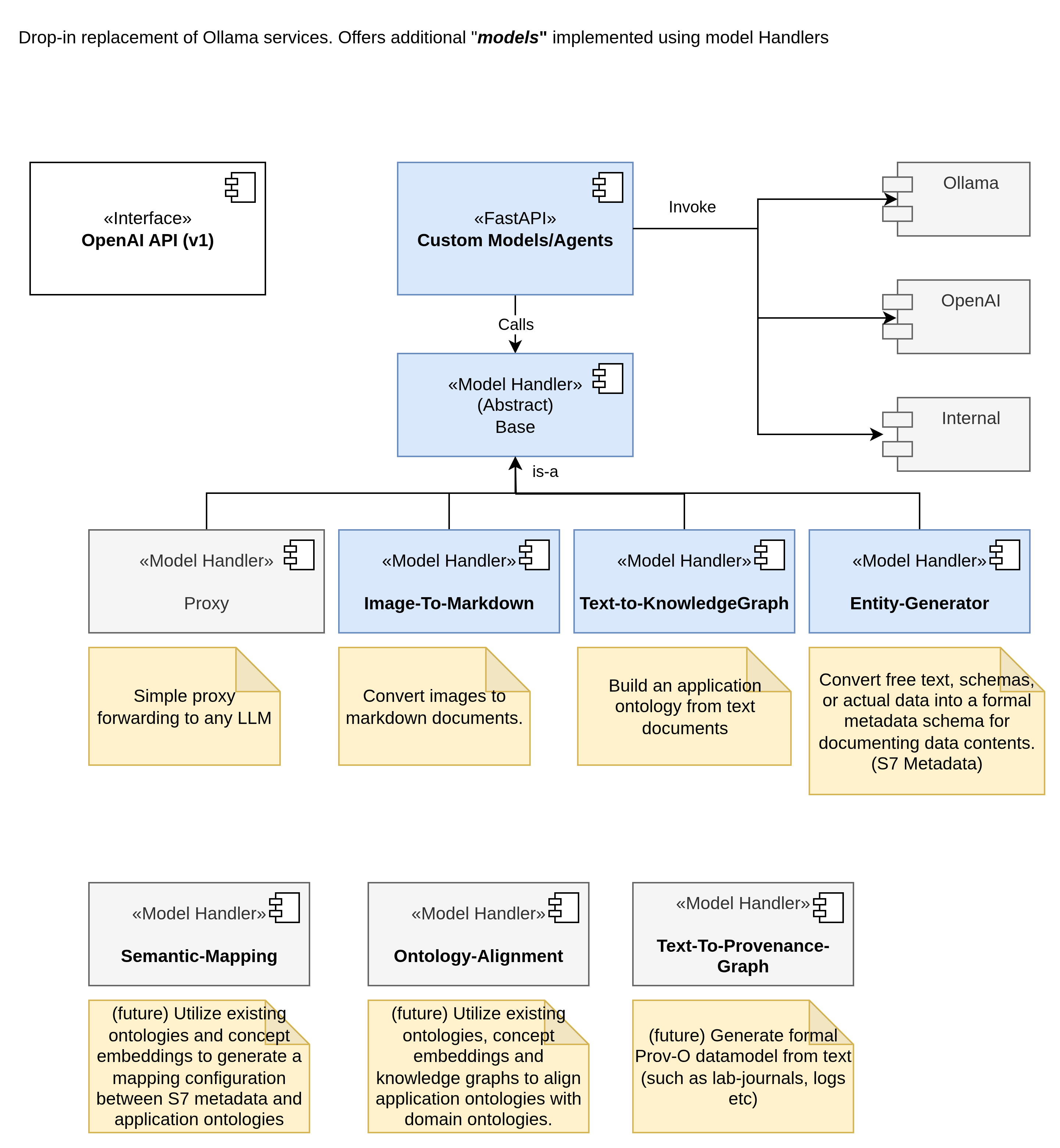
OpenAI-compatible interface, model handlers, and specialized generator stack.
Move faster with a reproducible data pipeline.
Step 1
Raw Data Generation
Step 2
Structure and Validate
Step 3
FAIR-Aligned Asset
Step 4
Analytics and Decisions
Automate the creation of audit-ready provenance trails from scattered lab notes.
Feed simulation frameworks with structured, validated, and unit-aligned data inputs.
Align terminology and data structures across global R&D centers automatically.
Enable 'what did we learn?' queries across thousands of past experiments.
Blobfish addresses data quality bottlenecks in industrial R&D where teams need structured FAIR-aligned data for analytics and AI.
Proprietary model handlers and ontology workflows create a deep moat against generic LLM wrappers.
OpenAI v1-compatible APIs reduce integration work in existing MLOps stacks.
Driven by regulatory pressure (FAIR mandates) and the need for clean data to fuel AI initiatives.
A phased rollout strategy grows from marine operations into chemicals, materials, energy, manufacturing, and food tech.
Phase 1
SemanticMatter expands Blobfish into marine operations, providing a FAIR data backbone for offshore asset integrity. By turning inspection reports, sensor feeds, and maintenance histories into a unified knowledge graph, operators get traceable, machine-readable inputs for digital twins, risk models, and operational decision support.
Phase 2
SemanticMatter brings Blobfish into the heart of chemicals and materials R&D, creating a FAIR knowledge graph over experiments, formulations, and characterization data. By turning human-written lab notes and instrument outputs into machine-readable, ontology-aligned metadata, organizations gain a traceable memory of what was tried, what worked, and why, ready to power optimization models, scale-up decisions, and regulatory submissions.
Phase 3
SemanticMatter extends Blobfish into Energy, Manufacturing, and Food Tech as a FAIR data spine connecting lab, plant, and quality systems. By converting recipes, process logs, and QA data into a machine-readable, ontology-aligned knowledge graph, organizations gain a unified view of how process decisions impact yield, quality, and compliance, fueling optimization models, digital twins, and trustworthy reporting.
1
Upload files or stream data via API. We handle PDFs, images, SQL, and more.
2
LLM agents identify entities and relationships using domain-specific context.
3
Map local variables to standard ontologies (for example, QUDT and BFO) and enrich with external metadata.
4
Human-in-the-loop workflows allow experts to review and approve generated graphs.
5
Push validated knowledge graphs to data lakes, digital twins, or analytics platforms.
Blobfish exposes an OpenAI v1-compatible API. You can switch the base URL in clients such as LangChain or LlamaIndex to route relevant tasks to specialized handlers.
Blobfish supports community standards such as QUDT, BFO, and SOSA/SSN, plus custom OWL and RDF ontologies.
Yes. Blobfish can run in private VPC or on-premise infrastructure so data remains under your control.
A dedicated human-in-the-loop validation interface lets domain experts review, correct, and approve generated knowledge graphs.
A typical pilot starts with a scoped dataset, such as 50-100 lab notebooks or reports, followed by a technical scoping session.
Bring order to lab data
Work with teams building reusable knowledge assets for analytics, digital twins, and AI.